

Introduction
Apparently, I like doing sports forensic analysis. I must, since I'm clearly not doing it for the money. So here's a third installment, after my look at Derek Fisher's 0.4 shot and Mookie Betts's encounter with Houston's right field fans. This makes it two for three on forensic analyses done many many years after the fact, haha.
Let's set the stage: It's October 29, 2014. The San Francisco Giants and the Kansas City Royals are locked in a tightly contested winner-take-all Game 7 of the World Series. Both starting pitchers have long since been knocked out, and the Giants are clinging to a 3–2 lead in the bottom of the ninth. Giants ace pitcher Madison Bumgarner entered the game in the bottom of the fifth inning and hasn't left. He gave up a sharply rapped single to right to Omar Infante, then subsequently mowed down twelve straight batters.
Here, in the bottom of the ninth, he strikes out Eric Hosmer for the first out and gets Billy Butler to foul out weakly to first base for the second out. Bumgarner has now retired fourteen straight batters and needs just one more to record a five-inning save and earn the Giants their third title in five seasons.
But Alex Gordon, after fouling off the first pitch, cues a tailing liner into left center that dies just in front of the hard-charging center fielder Gregor Blanco, then bounces by him toward the wall in left center. He pulls up as it appears clear that left fielder Juan Pérez is going to beat him to the ball.
Pérez boots the ball as he rushes to pick it up, though, and a tense couple of seconds pass before he succeeds and finally gets the ball back to shortstop Brandon Crawford in shallow left. By the time he does so, Gordon is pulling into third base on a single plus two-base error, having gotten the stop sign from third base coach Mike Jirschele. Crawford checks to make sure that Gordon doesn't keep running, then throws routinely to first baseman Brandon Belt near the pitcher's mound.
Salvador Pérez (hereafter "Salvy," his nickname, to avoid confusion with Juan Pérez) now comes to bat, and there follow six specimens of what writer Wade Kapszukiewicz calls "Golden Pitches": pitches whose end result could potentially win the World Series for either team. Such pitches can only occur in the bottom of the ninth or any later inning of Game 7. If Salvy hits a home run, the Royals win the World Series. If he makes an out without first driving in Gordon, the Giants win the World Series.
Bumgarner goes to a tactic that has been successful all game for him: climbing the ladder on his high fastball and daring the Royals to hit it. Salvy swings repeatedly at pitches that are nearly neck high, and on the sixth pitch of the at-bat (and the 68th pitch of Bumgarner's appearance), he finally fouls out meekly to third baseman Pablo Sandoval, Gordon is stranded at third, and the Giants win.
In the aftermath of the game, and indeed all throughout the offseason, Jirschele and Royals manager Ned Yost were repeatedly asked whether they could have or should have sent Gordon home on that second-to-last play. Both were adamant that they made the right decision to hold Gordon, but the fact that Salvy never seemed to be able to contend on an equal footing against Bumgarner in this final at-bat sustained the fervent wish that Gordon had gone home.
But should he have? The question is a tantalizing one and touches on many notions of tactics and strategy. In this post, I'll analyze the game footage and other media and create a framework for deciding whether the Royals would have been better off sending Gordon home.
Technology and Stuff
The first order of business is to establish the basic facts of the play. How long after the crack of the bat did Gordon take to reach first base, second base, third base? When did Crawford field the throw from Pérez in left field? How far was he from home plate at that time? And how long would it take him to deliver the ball to catcher Buster Posey at home, if Gordon were to run home?
The play's timing can be determined by counting frames of the MLB video of the play and its various live-speed replays. Here's the play on YouTube; this video is encoded at 30 frames per second, so by counting frames from the initial contact with the bat and dividing by 30 frames per second, we can construct a timeline of the play:
- 0.00 s: crack of bat
- 2.97 s: ball falls in front of Blanco
- 4.00 s: ball bounces a second time, then rolls to fence
- 4.73 s: Gordon touches first base
- 6.63 s: ball reaches the fence
- 7.80 s: Pérez boots ball along fence
- 8.43 s: Gordon touches second base
- 10.00 s: Gordon turns to look at the play in the outfield (approx)
- 10.17 s: Pérez throws ball to cutoff
- 10.67 s: Jirschele begins raising his hands (approx)
- 11.17 s: Jirschele's hands are now up to hold Gordon (approx)
- 11.77 s: Crawford fields ball (about 212 feet from home plate)
- 12.17 s: Gordon stops at third base
- 13.53 s: Crawford throws to Belt
- 14.93 s: Belt fields ball and time is called
For some of these events, I also used, as secondary event and time sources, this MLB Statcast video, this fan video from just above the Giants' dugout, and this other fan video from the left field stands, all encoded at 30 frames per second. None of these times are accurate to any better than 1/30 of a second, therefore, though they've been rounded to the nearest hundredth to simplify the arithmetic. I estimate these times have an error of about ±0.05 seconds.
Incidentally, ESPN also analyzed the MLB video, and somehow got 8.30 seconds for Gordon to touch second. I've measured it a few times, and I don't see how they get that. The rest of our times are within my ±0.05 second error bar, including notably the time it took for Gordon to reach third base, which makes that 0.13 second discrepancy even odder. I'll use my figure of 8.43 seconds, to keep the methodology consistent.
Next, how far was Crawford as he fielded the throw and prepared to throw home if necessary? For this analysis, as a reference frame for determining event locations, I used the special groundskeeping design for the World Series games at Kauffman Field in Kansas City, which is depicted here (click to enlarge):

Gorgeous setting, by the way. This photo is from before Game 1, but I don't think the pattern changed for Game 7. As you can see, left field (and right field, but we're focusing on left field) is criss-crossed with a lattice of intersecting light and dark bands, which will serve as a grid for us to identify the locations of players and events during the play. We'll need to fix this grid on a diagram of Kauffman Field, which we create from Google Maps's satellite view (click to enlarge):

North is up. This groundskeeping pattern is not the one from the 2014 World Series, so we can't simply use the satellite image as is. Rather, by comparing the two images, we create an overlay for the World Series groundskeeping pattern. I've rotated the image counter-clockwise by 2 degrees to line the field up horizontally and vertically, then added the relevant portion of the pattern as green outlines (click to enlarge):
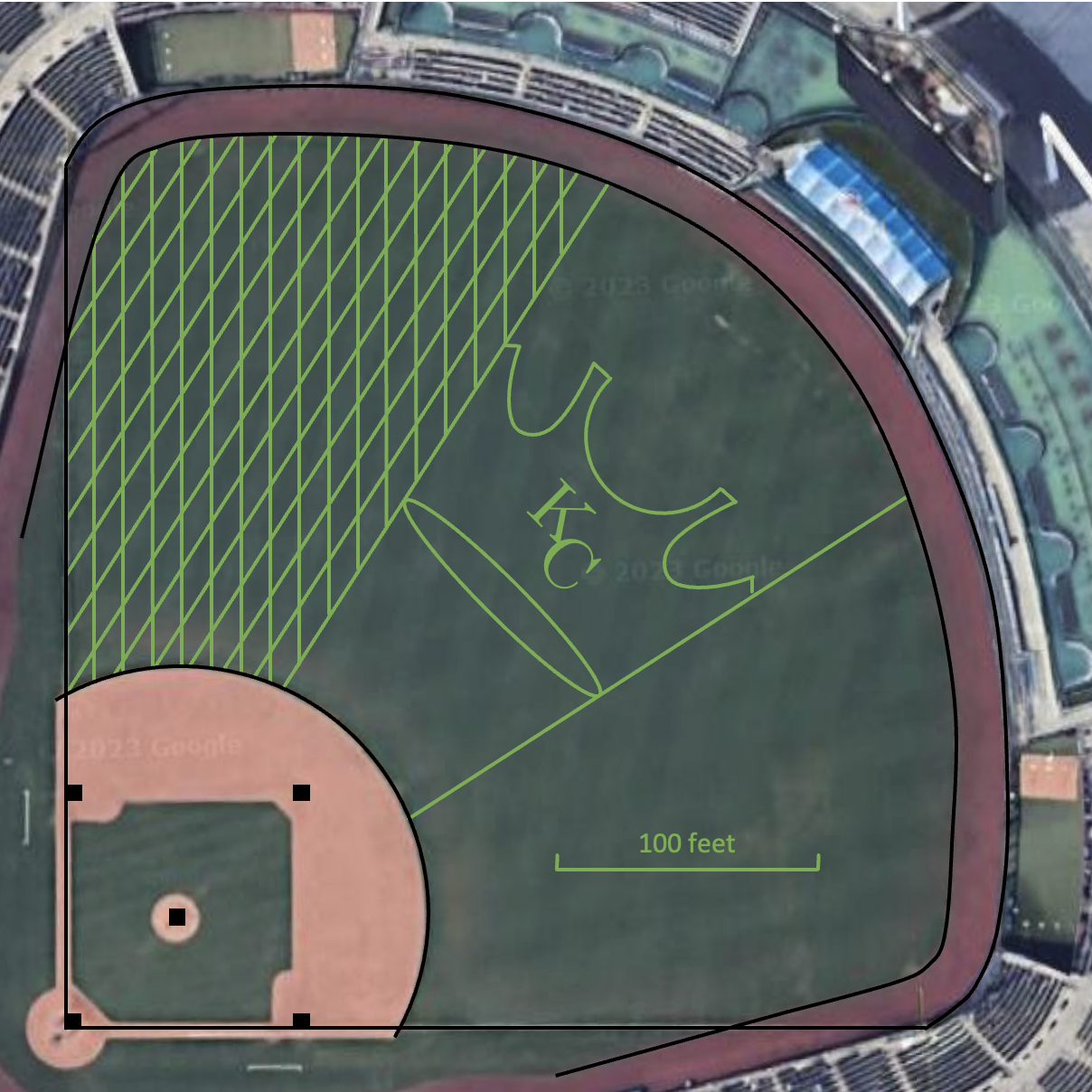
Now that we have the grid laid out, we dispense with the satellite view, go through the video, and place the various events on our overlay (click to enlarge):

These events include positions of Blanco (B1 and B2), Pérez (P1, P2, and P3), and Crawford (C1 and C2) throughout the play, as well as the path of the hit ball through the outfield (H1, H2, H3, and H4). We now remove the grid as well, and connect the main events (click to enlarge):

The throw that Crawford would have had to make is the dotted orange arrow to home. By measuring against the 100-foot scale, we see that the throw is about 212 feet. I estimate this method to have an error of maybe ±10 feet, so it's somewhere between 202 feet and 222 feet, but the rest of my analysis will assume a distance of 212 feet.
That's well outside most casual estimates. ESPN's article gauged it at 180 feet, which is 15 percent low. My first off-the-cuff estimate was 140 feet, which is on the skinned infield and ridiculously low, though it was echoed by multiple commentators; then, I guessed 180 feet, in line with ESPN's estimate. Crawford himself thought he was 30 to 40 feet out onto the outfield grass, which would put him 180 to 190 feet from home plate. The longer throw makes the potential play closer than otherwise—but is it close enough to send Gordon?
So Much Crawford
The critical factor is how long Crawford reasonably needs to turn that throw around to home plate. Fortunately, we have plays to compare this one to. The closest play I could find is from September 9, 2016, with the Arizona Diamondbacks hosting the Giants. In the bottom of the seventh inning, with the Giants leading 5–4, Chris Owings hits a fly ball to deep center that bounces off the glove of Denard Span. Socrates Brito scores easily from second base to tie the game, and Owings tries to come all the way around to score also, but he's nipped at the plate by a strong throw from Crawford. (The game went into extra innings tied at 5, and the Giants eventually won 7–6 in 12 innings, so the play turned out to be critical.) Again, we can create a timeline:
- 0.00 s: crack of bat
- 11.47 s: Crawford fields ball (about 235 feet from home plate)
- 12.20 s: Crawford throws ball
- 14.33 s: Posey fields ball
- 14.80 s: Posey applies tag
- 14.93 s: Owings reaches home plate (already out)
This play is almost directly behind second base and there is a convenient sequence of 25 light and dark diamonds, again created by groundskeeping. Crawford is in the middle of the ninth diamond, counting from the edge of the skinned infield, at 155 feet—the skinned infield is a partial circle with a 95-foot radius centered on the pitching rubber—to the edge of the 16-foot warning track in deep center, at 391 feet. That gives us our final figure of 235 feet (again, ±10 feet).
On this play, Crawford took 0.73 seconds to throw the relay, which traveled 235 feet in 2.13 seconds, for an average speed of about 110 feet per second, almost exactly 75 mph. Posey then needed an additional 0.47 seconds to tag Owings. When Posey fielded the ball, Owings was about 13 feet from home plate (that's the radius of the circle surrounding home plate), and he applied the tag when Owings was about 3 feet from home plate.
It's worth noting that a thrown baseball loses a lot of velocity in the air, about 15 percent per second at typical speeds. Crawford probably threw the ball at around 90 mph, and it slowed down to around 60 mph by the time it reached Posey.
There is also a play from September 7, 2013,
in the top of the eighth inning of a game in San Francisco between the
Giants and Diamondbacks, where Crawford relays a throw from center
fielder Ángel Pagán. It's difficult to determine Crawford's distance from home plate;
I estimate that he's 195 feet away. The throw
covers 1.77 seconds in the air, which is consistent with an average speed of 75 mph, but because of the uncertainty in the distance, it's not my primary comparison.
Additionally, in the second inning of this Game 7, Crawford threw a relay to home plate from right fielder Hunter Pence. Again, it's hard to tell just where Crawford is, but I estimate he's 50 feet past the skinned infield, or 205 feet from home plate, and the throw took 1.90 seconds to get there, an average speed of about 74 mph. The throw was not in time to catch Billy Butler scoring the Royals' first run, but Butler was already halfway from third base to home plate when Crawford made his throw.
Later, in the fourth inning, Crawford made a snap throw to first to complete a sparkling double play started by second baseman Joe Panik, who made a catch diving to his right and glove flipped the ball directly to Crawford. That throw was made under different circumstances, but Crawford's performance was similar: As this MLB Statcast video indicates, he needed 0.77 seconds to throw the relay, which he did at 72 mph, though he was forced to throw it flat-footed.
Reconstructing the Sequence
With all this in mind, let's run through the play again, annotated this time with the sequence and commentary (click to enlarge):

- At 0.00 seconds, Gordon hits the ball to left center (blue dashed line). The ball is hit near the end of the bat, which causes it to tail away toward left field; see the path above. Blanco initially thinks he can catch the ball on the fly, and he charges forward. Pérez also thinks Blanco will catch the ball and starts jogging toward the infield; Posey similarly jogs to the mound, anticipating a celebration involving the notorious Posey Hug.
- By the time the ball hits the ground at 2.97 seconds, Blanco has realized that he can't catch up to the ball, but it's too late for him to pull up to play it on the bounce. It squirts right by him toward the fence. This counters the notion that by running hard out of the
gate, Gordon would risk being caught between
first and second; he would never get to first base within 2.97 seconds. Pérez has to turn around and sprint toward the ball, and Blanco pulls up as he realizes he can't get there any quicker than Pérez.
- At 4.00 seconds, the ball bounces a second time. Had Blanco played the ball safely, he would have caught it at about 3.90 seconds. He would have been about 210 feet from second base and would have gotten the ball back well in time to keep Gordon from advancing past first base. In reality, the ball continues bouncing toward the wall, Pérez in hot pursuit.
- Meanwhile, Gordon has run toward first base, but not at top speed. At 4.73 seconds, he reaches first base, having seen the ball bounce once and then twice. At this point, Gordon knows he'll get to at least second and has a good chance at third. Posey returns to the plate for a potential play, and Bumgarner retreats toward the backstop to back him up. Crawford began the play at the edge of the skinned infield, but now runs out to short left field to act as the primary relay. Panik sets up about 40 feet behind him as the secondary cutoff.
- At 6.63 seconds, the ball reaches the fence. Pérez gets there shortly thereafter, but at 7.80 seconds, he boots the ball about 10 feet leftward along the fence. However, even if he fields it cleanly, he is over 300 feet from third base. It would take a phenomenal throw to nail Gordon there, even with Crawford relaying. Blanco's misplay is almost solely responsible for Gordon advancing, and indeed the official scorer assigned an error only to Blanco, not Pérez.
- At 8.43 seconds, Gordon reaches second base. He stumbles slightly as he rounds the bag, but regains his balance. He turns his head to the outfield to try to gauge the play, but it turns out he can't see it clearly because of glare from the outfield display.
- At 10.17 seconds, Pérez has finally secured the ball and throws it (orange dashed line) to the cutoff man Crawford, who stands 212 feet from home plate. Panik is behind him, keeping an eye on the play in left field as well as Gordon's progress on the basepath. Meanwhile, Jirschele starts raising his hands, and at 11.17 seconds (give or take), the stop sign is up.
- At 11.77 seconds, Crawford fields the throw, having had to "pick" it on the short hop. Normally, the cutoff man is supposed to avoid trying to catch a throw on the short hop; he should let it go to the secondary cutoff man to avoid the ball bouncing away and letting the run score uncontested. Crawford later said, "Nothing against Panik, who was the second cutoff man on the play, but I was going to catch the ball unless I couldn't catch it [that is, literally couldn't reach it]." Panik puts his hands up to forestall an immediate throw home.
- At 12.17 seconds, Gordon pulls in at third base. Crawford has turned around, poised to throw home, but after seeing Panik's signal and checking that Gordon isn't going, he tosses a more routine 140-foot throw at 13.53 seconds to Belt, who catches it at 14.93 seconds. The umpires call time.
So much for what actually happened. It's time to speculate! Suppose that Crawford again takes 0.73 seconds to turn around his relay throw, which we'll suppose averages 75 mph. (At 212 feet, this throw is somewhat shorter than our comparison, but it's close enough that the difference is probably minor. If anything, however, this approximation overestimates the time elapsed by the throw.) He would then make that throw to the plate at 12.50 seconds, and it would be fielded by Posey 1.92 seconds later, at 14.42 seconds.
Would that be in time to catch Gordon? He actually got into third base at 12.17 seconds. Let's suppose he could have gotten home in another 3.50 seconds, landing him there at 15.67 seconds. He would be more than 30 feet from home plate as the ball reaches Posey's glove. That gives Posey more than a second to apply the tag; in the play on Owings, Posey needed less than half a second to apply the tag.
The What-If Scenario
But suppose that Jirschele hadn't put on the stop sign, and encouraged Gordon to run all the way home. It remains to be seen whether that would be a good idea, but suppose he did that. Let's also assume that Gordon ran flat out all the way and didn't stumble going around second. Gordon would then have reached third earlier, but how much earlier?
On a triple the previous season, on April 5, 2013, in which Gordon seems to have run hard the whole way, he slid into third base 11.90 seconds after the crack of the bat. (AZ Central ran an article on this play, and somehow measured the run at 11.03 seconds. Again, I'll stick with 11.90 seconds to keep the methodology consistent.) If he ran the same way in Game 7, his time to home plate would be longer, by about the time on one of his intermediate legs (first to second, or second to third). As far as I can tell, Gordon is rarely better than 3.60 seconds on any of these—his intermediate first-to-second leg in Game 7 was 3.70 seconds—but again, let's say it adds 3.50 seconds. That gets him to home plate at 15.40 seconds, and still gives Posey nearly a full second to apply the tag. Gordon would be about 25 feet from home plate when Posey fielded Crawford's throw.
All in all, it seems as though Posey would tag Gordon comfortably out in almost any circumstance—barring an error. So how often does Crawford uncork a wild throw? In 2014, Crawford committed 21 errors, on 634 opportunities, which included 185 putouts and 428 assists (throws that lead to a putout). It's unlikely that all 21 errors were throwing errors, and also unlikely that he only threw 428 times, but let's assume both of those are true to put an upper bound on his error rate. In that case, he would have 21 errors on 449 throws, for an error rate of 0.047, a bit under 5 percent. You'd never send a runner if you thought his chances of making it were under 5 percent.
Of course, most of those throws were from shortstop to first base, a throw that averages about 120 feet. The throw in this case was 80 percent further, certainly well within Crawford's range, but probably it increases his error rate. Let's say it doubles it, to 10 percent. Is that high enough to send Gordon?
Probably not. Statistically, for the 2010–2015 era, with a runner on third base and two outs, that runner scores about 26 percent of the time. That itself should be enough to settle the matter, but there's more. In that situation, the team scores an additional run (or more) about 7 percent of the time; otherwise, in this case, the game goes to extra innings and it's a coin flip as to who wins. Maybe the home team has an edge, but it's small. Rob Mains's study in Baseball Prospectus suggested it was about 52–48 to the home team (less than it is in regulation, interestingly).
That means that with Gordon stopping at third, the Royals have about a 17 percent chance of eventually winning the game (a win in nine innings with 7 percent probability, and a win in extras with 0.52 times 0.19, or 10 percent). If he goes home and makes it, the Royals have about a 55 percent chance of eventually winning the game (a win in nine innings with 7 percent probability, and a win in extras with 0.52 times 0.93, or 48 percent). If he goes home and is tagged out, of course, the Royals simply lose.
So in order for it to be worth it to send Gordon, he has to have a success rate of at least 17/55 or 31 percent. Incidentally, Nate Silver did only this part of the analysis, arriving at a figure of 30 percent using slightly older scoring statistics. (He then simply assumed that Gordon would score more often than that and therefore advocated sending him. Very lazy, Nate!) David Freed, writing for the Harvard Sports Analytics Collective, determined a threshold of 29.6 percent based on more specific statistics (though they use the dramatic underestimate that Crawford stands 140 feet from home plate for the rest of their analysis). So there's general agreement on that roughly 30 percent figure.
I don't see Gordon scoring with anything like that probability. Maybe the long throw increases Crawford's error rate a bit more than double, maybe that 30 percent can be edged a little downward because Salvy was hit by a pitch earlier in the game, but I just don't think those two lines cross. Crawford was no playoff newbie in 2014, and sending Gordon just to force him to make a play isn't the percentage call. I'm sympathetic to those who wanted Gordon to be sent home for the excitement value, but it should be recognized for what it is: a gut reaction call that goes against both traditional baseball judgment and post-mortem analysis.
Thursday Morning Third-Base Coaching
Afterwards, there were a lot of fans who insisted that not only should Gordon have been sent home, but that people who agreed with holding Gordon were flat out wrong. Frankly, I think that's a little crazy. It comes from thinking that because Salvy did in fact pop out, he was destined to pop out. Even having been hit by a pitch back in the second inning, Salvy had a chance of walking it off against Bumgarner. He had hit a homer back in Game 1, accounting for the Royals' only run against Bumgarner. And there's the history of Kirk Gibson hitting a home run off the great Dennis Eckersley in Game 1 of the 1988 World Series. Does anyone watching that video think that either of Gibson's legs was in better shape than Salvy's? Salvy would go on to earn the 2015 World Series MVP when the Royals came right back to win the title.
Other fans thought that Bumgarner's admittedly dominant performance argued for a more aggressive stance on sending Gordon home. But again, this smacks of after-the-fact destiny. Bumgarner had already thrown 62 pitches (before facing Salvy), after throwing 117 pitches in Game 5 just three nights earlier. It was by no means a foregone conclusion that he was unhittable. Certainly Yost thought they would get to Bumgarner.
Tim Kurkjian wrote the ESPN article that analyzed the video for timings. That same article also collected quotes and observations from many of the principals involved. To a man, they all agreed that the right call was made. Most of those interviewed thought it wasn't close. (Yost thought Gordon would have been out by 40 feet, which I think is a bit of an overestimate.) The only player who was even halfway wondering what would have happened was Gordon himself, and by his own admission, he couldn't clearly see what was going on in the play at the time, because the bright display in center field cast a glare that obscured Blanco's and Perez's hijinks.
Some other observations out of that article: Jirschele claimed that he was waiting for Crawford to field the throw from Pérez cleanly before holding Gordon up. But Jirschele began holding his hands up over a second before the ball had gotten to Crawford. I suspect he felt Crawford's chances of fielding the throw cleanly were too high not to put the stop sign up before it was too late; if so, his intuition was vindicated.
Gordon recalls running hard out of the box. It didn't seem that way to most observers, including Jirschele, and in fact some fans thought he was just jogging to first until the ball dropped. The 4.73 second time to first base suggests that he was moving faster than that, but not running all out. The explanation is pretty straightforward—Gordon clearly thought that he could expect no more than a single and ran accordingly—but the charge that under the circumstances he should have been running harder than he did is a reasonable one. As we've seen, though, even his fastest run would have had a hard time beating a halfway accurate throw home.
During the following offseason, a local college baseball team reenacted the play and nailed the runner five times out of six, failing only the first attempt on an overthrow. Some fans pointed to that one failure as an additional point in favor of sending Gordon, but that first reenactment got the timing wrong; the shortstop didn't throw until the runner was nearly a full second past third base. (This video is encoded at 24 frames per second.) Seeing the runner that far ahead may have caused the shortstop to rush the throw; also, with that extra time, the catcher could plausibly have retreated to catch the ball properly and race back to tag the runner. This experiment differed too much from the original game conditions to be of much probative value, though.
Finally, five years after the game, Jirschele revisited the call, affirming that he made the right call, and capping it all with an amusing anecdote. But the plain fact of the matter is that if he had sent Gordon home, there would very likely be no debate, and instead Jirschele would be held up as the Royals' third base coach who made the call that ended his team's season.































